从程序员到数据工程师,编写程序代码是一项基本功,但是编写冗长代码的过程也极大地消耗了开发者的耐心。
近来,有不少关于代码补全工具的消息爆出,例如,来自美国的 Kite,来自加拿大的 TabNine 等,一时间获得了不少程序员的关注。但其实很多人还并不知道,在这些国外产品不断被媒体推送的背后,有一款能力更为强大、更早将深度学习应用于代码补全的产品,一款源自中国的工具——aiXcoder,它的研发者们来自于北京大学。
在本文中,机器之心采访了项目总负责人北京大学计算机科学技术系副教授李戈,请他为读者朋友解读自动代码补全背后的技术,以及 aiXcoder 背后的技术特性和优势。
aiXcoder 官网:https://www.aixcoder.com
aiXcoder 的代码补全效果
我们先看看写 TensorFlow 时的代码补全效果:
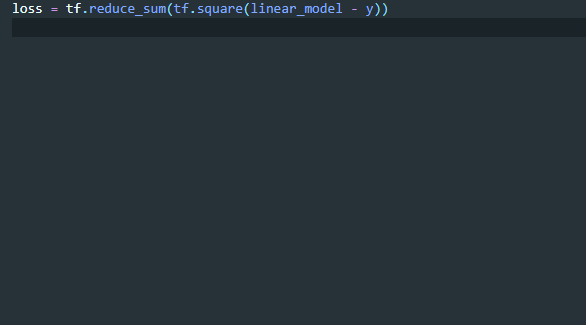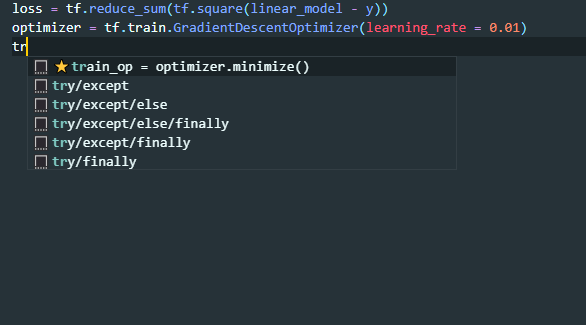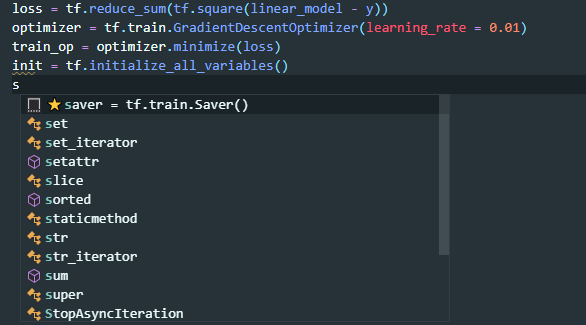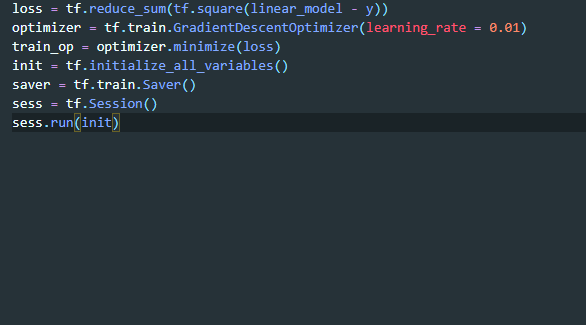
如上所示,aiXcoder 在 TensorFlow 的代码环境下能够直接「猜测」到模型建立后的一系列代码流程。例如,在定义了 loss 之后需要定义 optimizer,之后需要 train_op、init 方法,然后最终定义模型的保存方式 saver,以及开始运行计算图。这样一个流程基本上是深度学习开发者所知晓的,但是按照流程写下来非常繁琐。在 aiXcoder 的提示下,开发速度得到了提升。
aiXcoder 支持 Java、C++/C、Python、PHP、JavaScript 等语言,以插件的方式集成到现有的 IDE 中,如 Pycharm、Android Studio、VS Code、Eclipse、Webstorm、Sublime 等,插件的背后是一个强大的云端深度学习引擎。
针对开发者,该产品目前分为社区版、专业版和企业版。社区版是完全免费的,专业版也可以通过分享而免费获得。它们间的不同之处在于模型会不会继续学习,社区版主要利用事先训练好的公用模型做预测,而专业版则会根据用户的代码习惯及结构作进一步的调整。
企业版是 aiXcoder 功能最为强大的版本,它能够在企业内部的私有云中进行部署,并能够利用企业自己的代码来进行模型的优化训练,从而具有更高的准确率和运行性能。
aiXcoder 用起来怎么样
百闻不如一见,机器之心也对 aiXocder 进行了使用测试。
机器之心在 Pycharm 上试用了社区版/专业版,它们都是需要在线推断。不同的地方在于专业版还需要额外的内存,因为每一个 Pro 用户都需要额外的缓冲区来储存模型「学到的」用户习惯。当然,Pro 用户的缓冲区是是只有该插件能访问的。
使用体会
一般而言,当我们选择 Python 和 PyCharm 时,代码补全就自然用 IDE 自带的工具。使用 aiXcoder 第一个感受是它比自带的补全工具灵活得多,因为以前的补全主要体现在 Python 函数或其它包的 API,而 aiXcoder 还会预测变量名是什么、运算是什么、想调用的函数又是什么。
虽然代码补全的推断过程全是在云端完成的,但在我们的使用中,一般网络环境甚至 4G 都能有实时的反馈,所以补全速度上基本和 Pycharm 自带的工具差不多。李戈教授表示,目前 aiXcoder 绝大多数都能在 200ms 左右得到反馈,有部分地区的用户由于网络延迟问题可能会感觉到卡顿,aiXcoder 正在全国各个主要城市部署服务器,以提升用户体验。同时,aiXcoder 团队也特别关注模型压缩技术,希望把基于 CPU 的推理运算时间压缩到可接受的程度,从而推出能够在 CPU 上运行的本地版。
总体而言,aiXcoder 提供的补全功能在预测变量名、函数名或关键字等效果上确实非常灵活,而且它还会学习开发者的代码风格与编程模式,因此效果还是挺好的。
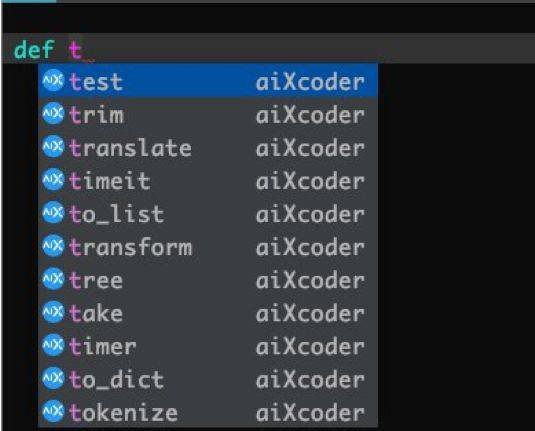
如下是自动补全的一些候选,一些函数名称可能是开发者之间经常使用的,因此得到了推荐:
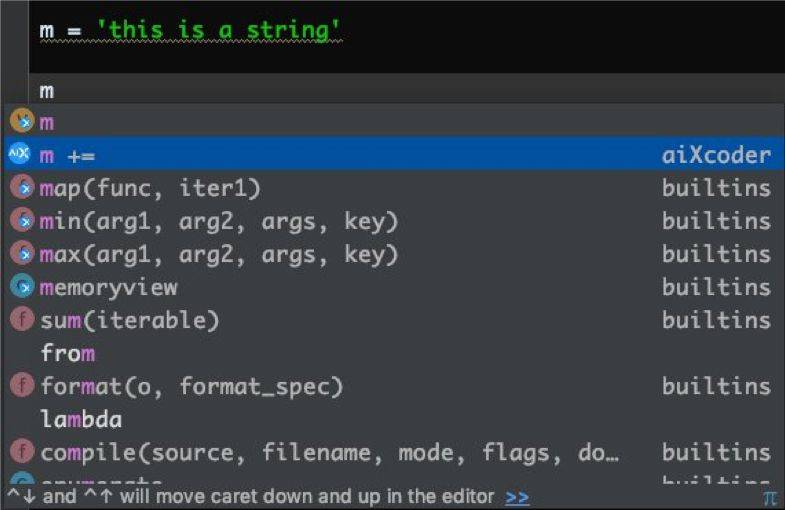
对于一些变量,aiXcoder 可根据变量类型提出该变量可能的操作,比如,对于下图的变量「m」,aiXcoder 提出了一个对字符串进行增加的代码:
对比测评
aiXcoder 官方也将产品和其他代码补全工具进行了对比,包括 Kite 和 TabNine 等。
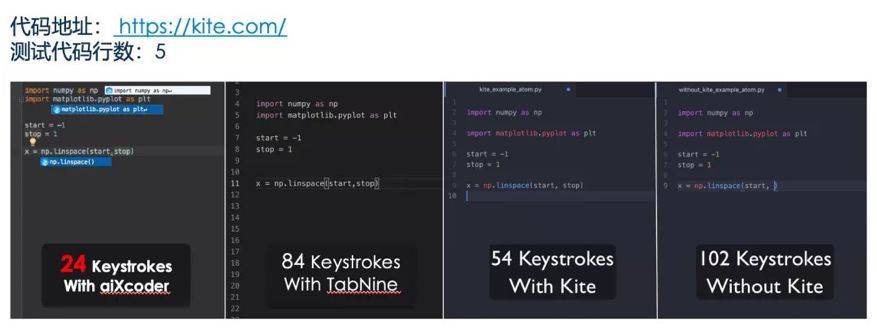
在对比过程中,aiXcoder 会使用 Kite 或 TabNine 官方提供的示例代码,并测试完成这段代码到底需要多少次按键。结果表明,aiXcoder 较其他插件在效率上提升 1.5 倍以上。
aiXcoder 是如何打造的
能够实现高效代码补全的 aiXcoder,背后有着强大的技术支撑。据李戈教授介绍,aiXcoder 很早就试过了语言模型,将代码视为一种语言从而直接建模,这就和 Deep TabNine 一样。但是研究者很快发现,只有语言模型是行不通的,它总会提出一些毫无意义、很不科学的补全建议。为此,aiXcoder 融合了基于序列的程序代码语言模型、基于抽象语法树和程序逻辑关系的图神经网络等方法,共同打造一个完整的系统。
为什么直接生成代码是困难的
如果深度学习模型能根据开发者的意图,以端到端的方式直接生成对应的代码,那么这样的模型会很「优雅」。但是经过研究发现,这样的任务需求是很难实现的,这和任务本身所依赖的数据的性质有关系。
李戈教授从机器学习所依赖的数据性质的角度,对代码生成任务和传统的图像处理任务、自然语言处理任务的不同,给出一种较为形象化的解释。

对于图像识别或图像分类任务而言,机器学习的目标是建立一个连续的数据集(图像数据)到一个近乎连续的、有着接近清晰边界的数据集(标签)之间的映射关系。
这样一来,由于图像数据异常的稠密,而标签集又有足够清晰的边界,那么这就相当于一个标签拥有大量的数据可以学习。这样的映射关系是比较容易建立的,这也是机器学习中和图像相关的任务相对较为容易完成的原因。
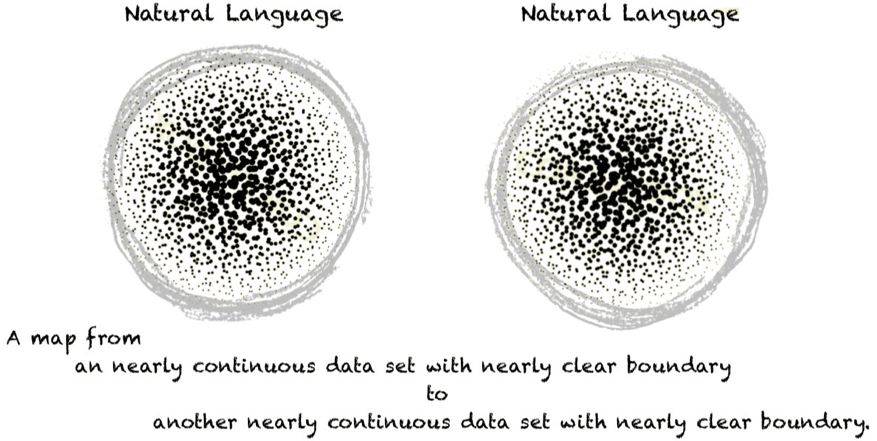
对于自然语言处理任务而言,机器学习需要从一个较为连续的(离散度高于图像)、有着较清晰边界的数据集建立与另一个较为连续的、有着较清晰的边界的数据集之间的映射关系。
而由于自然语言处理中的文本数据相比图像数据更为稀疏,因此自然语言处理相关的任务更难取得较好的模型性能。
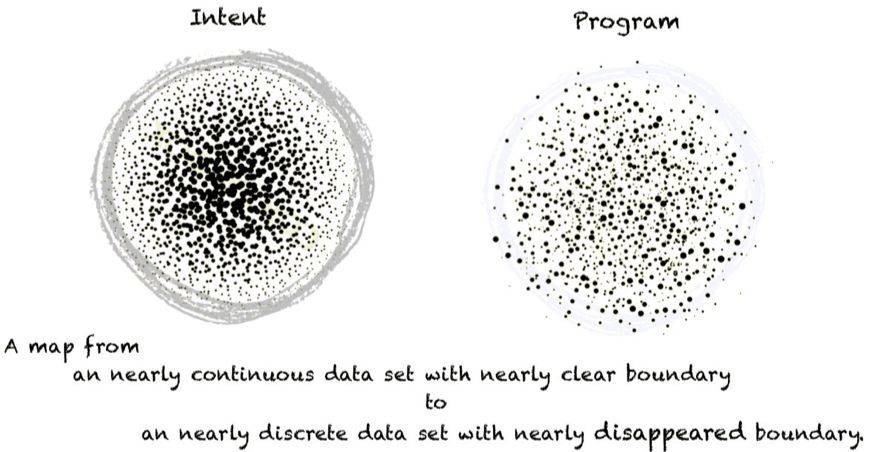
但是在代码生成方面,从编程者的意图(intent)生成程序代码的问题,可以看做是「程序员意图空间」到「程序代码空间」的映射,其中意图可以是由自然语言描述的信息。如上图所示,这是从一个较为连续的、有着较清晰边界的数据集,向一个更加离散而没有清晰边界的数据集进行映射。
换句话说,尽管代码生成的意图较为清楚,但是实现该意图的代码数据却比较稀疏,而且即便对于相同的意图,其对应的实现代码之间仍存在较大差距,因此这样的任务是非常难学习的。
为此,在 aiXcoder 的实际实现中,对不同应用领域的代码都采用了特定的模型,它们仅使用该领域的数据进行训练。例如,对 TensorFlow 或 PyTorch 等框架也有其特定的代码补全模型。这样做的主要目的就是加强程序分布的稠密性,在特定领域下,代码分布更加接近连续性。
可见,根据编程者的「意图」来「直接」生成完整代码是非常困难的,但李戈教授表示,可以用类似的技术来辅助人类程序员来编写代码,我们可以从程序员已经写下的代码中获取程序员的「编程意图」,然后综合分析代码,的结构信息、变量引用信息、API 序列信息、继承关系信息等等,以自动生成后续代码。然而,在这个过程中,只有语言模型是远远不够的,还需要对很多其它代码特征进行分析,才能做好生成式的代码补全。
单纯的预训练语言模型又怎么样?
提起代码补全,有些人可能会下意识的认为这仅仅是一个普通的语言建模任务,模型只需要根据开发者之前写的代码预测之后的代码即可。因此使用最先进的预训练语言模型,再在代码数据上进行微调说不定是一种好方法。
但是李戈教授表示,这样的想法是远远不够的。预训练语言模型在代码补全任务中效果不佳,主要是因为代码补全任务本身存在诸多不同于自然语言分析任务的挑战。
首先是代码文本中存在的语义抽象性问题。代码的语义(功能语义)与其字面表示之间存在更大的差距。我们无法根据字面确定代码的准确语义。例如,在代码中,只改变一个字符就有可能完全改变整行代码的功能,因此处理代码的语言并准确提取其含义相比自然语言处理任务更棘手。
f = open('word_ids.txt','r')
f = open('word_ids.txt','w')
上图所示,在 Python 代码中,打开某个文件时使用「r」和「w」会实现完全不同的功能。
此外,代码的功能语义难以进行具体的表达和刻画,而且代码功能语义的表达方式多种多样。例如,有多种代码的形式文本用于实现某个功能,不能说某一种代码是对的而另一种是错的。
list_a = [] for i in items:
result = test(i)
list_a.append(result)
list_a = [test(i) for i in items]
如图所示,实现 list_a 的代码可以是多种多样的,但语言模型会将它们学习为完全不同的表征。
同时,代码文本本身的结构非常复杂。例如,代码的语义与代码结构(如行与行的缩进)之间存在较大的关联性,代码语义依赖于代码结构进行表达。这是预训练语言模型难以表示的特征。
最后,代码具有演化性的特征。代码较自然语言的迭代速度更快,因此预训练语言模型不能够及时捕捉演化特征。
考虑到代码语言中的诸多特性,单纯的预训练语言模型无法得到非常好的效果。
核心技术
既然单独的语言模型不行,那么 aiXcoder 又结合了哪些技术,它又是靠什么来补全代码的?总体而言,aiXcoder 主要依赖于其特有的对程序代码进行学习的深度神经网络模型,该模型能够对程序的如下几类特征进行分析:
1 程序的结构语义特征
程序语言是一种结构性很强的语言,程序的结构信息也体现着程序的语义。例如,抽象语法树是对代码进行解析的一种较为通用的结构,它体现了代码的语义特征,aiXcoder 便充分利用了抽象语法树,对程序员已经写下的代码的语义进行解读。
2 程序元素间的逻辑关系
程序代码的不同元素之间存在着不同的关系,例如程序变量之间的引用关系、类之间的继承关系、方法与参数之间的调用关系等等。程序本身又可以表示为多种图,例如控制流图、数据流图、调用关系图等等。aiXcoder 借助图神经网络能够对程序元素之间的多种关系进行建模,从而能够对程序元素之间的复杂关系进行分析和推理。
3 程序语言序列模型
当然,程序语言也具有与自然语言相似的一面,因此可以利用程序标识符之间的序列关系建立程序语言模型。aiXcoder 也使用了最新的深度学习语言模型对程序中的序列信息进行建模。

在获得程序代码的各种特征之后,就该把这些特征输入深度神经网络进行分析了,但这并不容易,因为在输入神经网络之前需要把这些特征进行向量化表示。在研究过程中,北京大学提出了一系列解决程序语言成分相量化的办法,并且在国际上最早发表了相关的论文,这些都为 aiXcoder 的构造打下了基础。
团队介绍
李戈教授所在的北京大学高可信软件技术教育部重点实验室是国内顶尖的软件科学研究团队,是北京大学计算机软件与理论全国重点学科的主要支撑,其建设历史可以追溯到 1955 年,至今已有 60 多年的学术沉淀和积累。该团队在著名软件科学家杨芙清院士和梅宏院士的带领下,已经成长为该领域国际领先的研究团队。
基于深度学习的代码分析与生成一直是李戈教授的研究方向,也是北大高可信软件技术教育部重点实验室重点关注的领域,他们从 2013 年开始就开展了基于深度学习的代码分析研究,从 2015 年开始就将深度学习用于代码生成,是最开始进行相关研究的团队之一。该团队在 AAAI/IJCAI/ACL 等顶会上发表过很多代码生成的相关论文,这也是一大笔技术累积。

李戈教授是 aiXcoder 创始人,北京大学计算机科学技术系副教授,CCF 软件工程专委会秘书长,斯坦福大学计算机系人工智能实验室访问副教授。主要研究方向:程序分析,程序生成,深度学习。所在研究团队聚焦于基于机器学习概率模型的程序语言处理,在代码功能分析、代码自动补全、代码缺陷检测等方面取得并保持了国际上领先的研究成果。
来源:机器之心
 CCTV《对话新时代》:朱迅专访省心办创始人于景晨
CCTV《对话新时代》:朱迅专访省心办创始人于景晨